HedgeHunt
A platform where creators build treasure hunts and explorers solve them in the real world.
Product
HedgeHunt is a platform for designing and playing real-world treasure hunts. Creators describe a hunt in plain language and AI writes the steps, or they build them manually in a visual builder. Explorers solve them on mobile, following a GPS-guided map that unlocks each challenge only after they physically arrive.
Challenge
Two things had to work and survive failure. AI had to produce complete, playable hunts from a text prompt without manual fix-ups. GPS had to enforce the journey without trapping players when signal drops. And all of it had to stay stable while creators kept editing hunts that players were in the middle of solving.
Approach
Generation uses structured outputs with an enrichment pipeline that quietly simplifies steps when their data can't be filled in. Navigation runs through a state machine with soft escape valves, so bad signal never blocks progress. A versioning model separates drafts from live content: creators edit freely while explorers play a frozen snapshot. A server-side transform strips answer keys before anything reaches the client.
Outcome
Players open a link, walk outside, and finish an AI-generated hunt with GPS gating that degrades gracefully. Creators publish, roll back, and keep editing without disturbing active sessions. Live at hedgehunt.app.
Overview
The platform has three main pieces: a Builder where creators design hunts, an Explorer where players solve them on mobile, and a Backend API that controls game logic and progression. The Builder is a form-heavy React app for designing multi-step hunts. The Explorer is a mobile-first app that walks players through steps one at a time.
Creators start with an empty hunt and add steps. Each step is a different type of challenge.
- Clue
- Explorers solve a text riddle. No media, no location, just lateral thinking.
- Quiz
- Multiple choice or free-text answers. The server validates against stored correct answers.
- Mission
- GPS coordinates, photo capture, or audio recording. The explorer goes somewhere and proves it.
- Task
- Open-ended submissions that AI validates. No single correct answer.
The Builder includes a live preview: an iframe running the actual Explorer, with answer keys stripped by a server-side transform before anything reaches the client. When the hunt is ready, the creator publishes it.
Creator Journey
An explorer opens a hunt link and works through steps one at a time. Walk to a park entrance and photograph the sign. Answer a quiz about local history. Record an audio response explaining what you see. GPS, camera, and microphone all run through the browser. The explorer submits, the server validates, and the next step appears.
The server controls game progression. Each API response tells the Explorer what actions are available next. The Explorer follows those server-provided links. It never decides what comes next on its own.
Architecture
The three platform apps plus a marketing landing page all live in a TypeScript monorepo. They deploy independently but share types, UI, and the messaging layer through three packages.
- @hunthub/shared
- Single source of truth for all types and validation schemas. Generated from one OpenAPI spec. If the spec changes and an app doesn't update, CI catches it at build time.
- @hunthub/compass
- Shared design system. Wraps MUI's createTheme with custom tokens, typography, and component overrides. One import gives any app the full design system.
- @hunthub/player-sdk
- Communication layer between Builder and Explorer. Sends hunt data to the Explorer iframe through typed messages. A server-side transform strips answer keys before anything reaches the Explorer.
Type Generation
The generated types define what the API accepts, but the Builder's form state has different needs. A location field that's required in the API needs to be nullable in the form because the creator hasn't chosen a spot yet. Steps without a server ID need stable keys for React to track them. Two transform functions handle the conversion:
- On load, API data gains form keys and nullable settings
- On save, form artifacts are stripped and nulls convert back to omissions
UI components only touch form types. The API shape is never exposed to rendering code.
Hunts go through three states: Draft, Published, and Live. Publishing clones the current steps into a versioned snapshot. Releasing points live traffic to that snapshot. Rolling back swaps the pointer to a previous version. No data migration, no downtime.
Decisions
Hunt Versioning Model
Creators edit hunts while explorers are actively solving them. If a creator modifies step 3 while an explorer is on step 1, the explorer could eventually reach content that changed mid-session. I needed complete isolation between editing and playing.
- Single document model. One
Huntdocument with all steps embedded. Simple to query. But publishing means either deep-cloning the entire document (expensive, hard to track versions) or adding version flags to every field (complexity explosion). Editing and playing would share the same data. - Event sourcing. Store every edit as an event, reconstruct state on read. Powerful but overkill at this scale. Makes every read path more expensive for a problem that doesn't need temporal queries.
- Separate version documents.
Huntholds metadata and a pointer to the live version.HuntVersionholds the frozen content snapshot. Steps are linked per version.
Three models. Hunt is the master record with a liveVersion field pointing to whichever HuntVersion is currently live. Publishing clones the draft steps into a new HuntVersion. Releasing swaps the pointer. Rolling back swaps it to a different version.
The release itself is a single findOneAndUpdate:
const result = await Hunt.findOneAndUpdate(
{ huntId, liveVersion: currentLiveVersion },
{ liveVersion: version, releasedAt: new Date(), releasedBy: userId },
{ new: true, session }
);
if (!result) {
throw new ConflictError('Hunt was modified. Retry.');
}The filter liveVersion: currentLiveVersion acts as optimistic locking. If someone else released between the read and the write, the filter matches nothing and the server throws a conflict. No distributed locks, no queues. The same pattern protects saves, using the client's updatedAt timestamp to catch concurrent edits at both the hunt and step level.
Automatic version pruning protects against unbounded growth. Old published versions are cleaned up, but the currently live version is always protected from deletion.
More complex schema. Every read that needs step data requires two lookups (version, then steps). Publishing is heavier because it clones step documents. But version isolation is absolute. Creators can edit freely while explorers see consistent, frozen content. Rollback is a pointer swap.
Why MongoDB
Each challenge type has a completely different data shape. A Quiz has options, correct answers, and validation modes. A Mission has GPS coordinates, radius, and media requirements. A Task has AI prompts and audio settings. I needed storage that handles this polymorphism without fighting the schema.
- PostgreSQL with table-per-type inheritance. A base
stepstable joined toquiz_steps,mission_steps, etc. Strong typing via Prisma. But adding a new challenge type means a new migration, a new table, and updating every query that touches steps. - PostgreSQL with JSONB. One
stepstable with achallenge JSONBcolumn. Flexible storage, but Prisma doesn't validate JSONB contents. You lose type safety at the database layer. - MongoDB with embedded documents. Steps are documents. The challenge field holds sub-objects for each type. Only one is populated. Adding a new challenge type means adding a field. No migrations.
MongoDB. Challenges are naturally document-shaped with variable structures that map cleanly to embedded objects. Publishing clones step documents with a straightforward insertMany rather than a multi-table transaction.
- Numeric IDs. A
Countercollection withfindOneAndUpdateand$incgives sequential, race-condition-safe, human-readable IDs for URLs and display. - No JOINs. Every "join" is an explicit batch query using
$inon arrays of IDs, avoiding N+1 problems.withTransactioncovers the critical paths: publish, release, and delete. - TypeScript tradeoff. MongoDB's TypeScript support isn't as strong as Prisma's. But the OpenAPI spec is the source of truth, so Mongoose schemas just follow along.
No compile-time query validation like Prisma provides. Some denormalization is needed since you can't JOIN. But the polymorphic challenge structure maps naturally to documents, and the OpenAPI-first approach means type safety comes from the spec, not the ORM.
Explorer Format (PlayerExporter)
The full Step document contains everything: correct answers, AI validation prompts, scoring criteria, admin notes. Explorers must never see any of this. Filtering on the client is not an option because the data has already left the server. One missed field or a browser devtools inspection would leak answers.
- Client-side filtering. Send the full document, strip fields in the Explorer app. Fast to build. Fundamentally insecure. The data is already on the wire.
- GraphQL field-level auth. Let the client request only safe fields. Still risky if a field permission is misconfigured. A new sensitive field defaults to exposed unless someone remembers to restrict it.
- Server-side transformation. A dedicated function that takes a full
Stepand returns aStepPF(Player Format). The boundary is structural. The server never sends what it shouldn't.
PlayerExporter runs server-side. It takes a full Step and produces a StepPF containing only what the explorer needs: no answer keys, no AI prompts, no validation criteria. Quiz options are randomized so the order is consistent within a session but unpredictable across sessions.
The same exporter feeds two consumers: the play API and the builder preview. Both receive identical output. The preview always matches exactly what a real explorer would see.
Extra type definitions and a transformation function to maintain for every schema change. But the security boundary is structural, not behavioral. You can't accidentally leak answers because StepPF physically doesn't carry them. If a new sensitive field is added to Step, the compiler forces a decision about whether StepPF should include it.
Wayfinder: Enforcing the Journey
A treasure hunt where players answer from the couch is just a quiz. The physical journey is the product, so every step carries a target location and the Explorer has to navigate players there, detect arrival, and unlock the challenge only once they're on the spot. On paper that's straightforward. In practice, phone GPS drifts 50 to 150 metres indoors, jitters across the boundary of a radius, gets denied outright, and occasionally just stops reporting. The navigation layer had to sit at the core of the game loop and keep moving players forward even when signal didn't cooperate.
- Server-side verification. Every GPS poll becomes a round-trip. Strongest anti-cheat, but arrival detection now depends on network quality, and casual hunts don't have enough at stake to justify it.
- Hard client gate. Block progression until GPS confirms arrival. Simple, but a rigid gate strands real players every time signal misbehaves, which is often.
- Soft client gate with escape valves. Client-side haversine for arrival detection, written as an injectable service so a server-side version can slot in later without touching the UI. When GPS misbehaves, players fall through a chain of fallbacks instead of hitting a wall.
The Explorer runs a state machine around the GPS feed, covering the real failure modes: acquiring signal, permission denied, position stale, navigating, inside the target radius, arrived. Transitions are explicit. Arrival uses a hysteresis band: entering the radius counts as arrival, but the state only flips back to navigating once the player has moved roughly 30% further out. Without that buffer, a player hovering at the boundary watches the unlock button flicker on and off as GPS jitters across the line.
When signal drops or permission is denied, the player is never stuck. After three minutes without movement a help tip appears. After five, the player can flag the step to the creator and move on. Location is a soft gate, not a hard one.
Client verification means a motivated cheater can spoof arrival. For the audience (birthday hunts, tour guides, classrooms) that's not the threat model. If it ever becomes one, the injectable service swaps for a server-side version without touching the state machine or the UI.
Challenge Type System
Four challenge types (Clue, Quiz, Mission, Task) with completely different field schemas. Three things need to work at the same time:
- The builder lets creators switch a step between types without destroying shared data like title and description
- The API validates based on type
- The OpenAPI spec generates clean schemas for all four
- TypeScript discriminated union.
ClueStep | QuizStep | MissionStep | TaskStep. Clean type narrowing with exhaustiveswitchstatements. Each variant carries exactly the fields it needs. But OpenAPI codegen handles unions poorly. MongoDB stores one shape per document, so switching types means replacing the document. The builder form state would need to be destroyed and recreated on type change. - Shared object with nullable fields. One
Challengeshape with all four type sub-objects as optional. Only one is populated at a time. Switching types means nulling the old field and setting the new one. Same document, same form state.
Shared object. The schema marks clue, quiz, mission, and task as optional + nullable. A Zod discriminator at the API layer validates that exactly one is populated and matches the type field. The constraint is runtime, not compile-time.
This made three things simpler:
- OpenAPI generation works with one schema instead of union complexity
- MongoDB stores one document shape where partial updates work naturally
- The builder switches types by nulling one field and setting another. No document recreation, no form state loss
No compile-time exhaustiveness checking. If you access challenge.quiz when the type is actually mission, TypeScript won't stop you. I compensate with strict API validation and consistent access through helper functions that check the type before accessing the specific challenge field.
AI Integration
Two distinct AI use cases. Multiple providers handle different media types, and provider failures can never block an explorer mid-hunt.
- Validation. Checking explorer submissions for Missions (photos of specific locations or objects) and Tasks (audio recordings) where exact matching is impossible.
- Generation. Creating complete, playable hunts from a text prompt like "a treasure hunt around Central Park about American history."
- Validation with a single provider. Simpler integration. But a single point of failure. If OpenAI is down, all Mission and Task validation stops and explorers can't progress.
- Validation with multi-provider and hard failure. Multiple providers, reject submissions when AI is unavailable. Safe, but frustrating for explorers in the middle of a hunt.
- Validation with graceful degradation. Multiple providers, each specialized by media type. If all fail, auto-pass with a flag. Explorers never blocked.
- Generation with free-form JSON. Ask the LLM for JSON, parse, hope it validates. The model hallucinates field names, invents enum values, nests things wrong.
- Generation with structured outputs. Enforce the output schema during generation. Enrich with external data after.
Validation. GPT-4o handles text, Google Gemini handles image and audio. If a provider fails or times out, validation auto-passes with a fallbackUsed flag. Explorers are never blocked by infrastructure. The prompt also adapts to attempt count. Gentler early, more direct after the player has missed a few times, so the difficulty feels shaped by the player rather than fixed.
Generation. OpenAI Structured Outputs with a Zod schema derived from the API types. The schema leaves out any field the model can't produce reliably from text alone. Those get filled in after generation by an enrichment pipeline:
- External lookups translate descriptions into the missing data
- Only high-confidence results are accepted
- If enrichment fails for a step, the step falls back to a simpler form that doesn't need the data
Every generated hunt is immediately playable. If schema validation fails, one retry feeds the specific Zod errors back to the model.
Auto-pass on validation failure means a bad answer could slip through. But blocking explorers when AI is down is worse for the experience. The generation quality gate trades geographic coverage for accuracy. Some steps fall back to a simpler form without location data, but nothing requires manual fixes.
AI Hunt Editing
Generation creates a hunt from nothing. A creator types a prompt, the API returns a complete hunt. Editing is a different problem. The creator already has a hunt open in the Builder and wants to modify it with natural language. "Make step 3 harder." "Add a photo mission near the Eiffel Tower." "Remove the last two steps." The model needs to read the current state, decide what to change, and apply changes through the same backend services the Builder uses. I needed an approach that could handle multi-step edits without each tool call adding another round-trip to the model.
- Traditional agent loop. One model inference per tool call. The model reads the hunt, waits for the result, decides what to change, saves the updated version, waits again, then writes its summary. A three-tool edit needs four inferences. Every tool result feeds back into the context window, so the model re-reads the full hunt JSON on each turn.
- Client-side diffing. Send the full hunt to the model, get the modified version back, validate, save. No tool calling. But the model must reproduce every field it didn't touch. One dropped field and data is lost silently.
- Programmatic Tool Calling. The model writes a Python script upfront that handles all tool calls. Each call pauses execution while the backend runs it. Python resumes with the result in a local variable. Creative decisions happen once at code-writing time. The script is mechanical execution.
Claude's Programmatic Tool Calling. On the first inference, the model writes a Python script. The script reads the current hunt, modifies steps in memory, enriches any new location-based missions, and writes the updated steps back in a single atomic call. Each tool call pauses the script. The backend executes it against real services and resumes with the result in a local variable. When the script finishes, Claude reads the output and writes a summary on the second inference.
Traditional Agent Loop
Programmatic Tool Calling
Two inferences for any edit, regardless of how many tools it uses. Tool results stay in Python variables and never re-enter the context window. A five-tool edit costs the same as a one-tool edit.
I started with a fine-grained tool surface, one call per step mutation. Most of it turned out to be wasteful. Single-step mutations couldn't express reordering in one call, and they gave the model tempting partial-update paths that produced inconsistent hunts. I iterated down to a small read/write pair plus a batch enrichment call. The write tool accepts the full steps array and saves atomically. Add, remove, reorder, update, all one call. The atomic array replace was easier for the model to reason about and safer for the data.
Tied to Claude's code execution API. The model must produce valid Python in a single pass, so the system prompt needs precise tool documentation and examples. Container startup adds latency to the first call. But for edits that touch multiple steps and need enrichment, the inference reduction is significant. The model makes all creative decisions at code-writing time. Everything after that is execution.
Highlights
Play API
Each API response tells the Explorer what it can do next. The Explorer follows server-provided links and never decides on its own. Game rules live on the server, so they can change without touching the client.
{
"step": {
"id": 3,
"type": "mission",
"title": "Find the hidden statue",
"challenge": { "radius": 50 }
},
"_links": {
"submit": { "href": "/api/play/sessions/abc/submit", "method": "POST" },
"hint": { "href": "/api/play/sessions/abc/hint", "method": "GET" },
"skip": null
}
}Session Management
Sessions are locked to the hunt version that was live when the explorer started. Releasing a new version mid-play doesn't interrupt active explorers. localStorage persistence resumes from the last completed step.
Prefetching and LRU Cache
The Explorer prefetches next-step media with async decode() and an LRU cache. Step transitions feel instant because assets are already decoded.
Answer Validation
Six validators, one interface. Each challenge type maps to its own: fuzzy text matching for quiz inputs, GPS distance for location missions, AI analysis for image and audio. Adding a new challenge type means adding one entry to the map.
interface AnswerValidator {
validate(
submission: PlayerSubmission,
challenge: Challenge,
): Promise<ValidationResult>;
}
const validators: Record<AnswerType, AnswerValidator> = {
"quiz-choice": new ExactMatchValidator(),
"quiz-input": new LevenshteinValidator(),
"mission-location": new HaversineValidator(),
"mission-media": new AIImageValidator([gemini]),
"task-audio": new AIAudioValidator([gemini]),
"task-text": new AITextValidator([openai]),
};Hunt Activity
Creators had no visibility into how players interacted with their hunts. The backend captured session data as players progressed through steps, but none of it was surfaced. Anonymous sessions expire after 24 hours, so any analytics reading raw sessions directly would lose data over time. Every play event writes to two stores: a session record that expires and a running totals document that doesn't. The analytics service reads both, so recent sessions have full detail and lifetime metrics are always accurate.
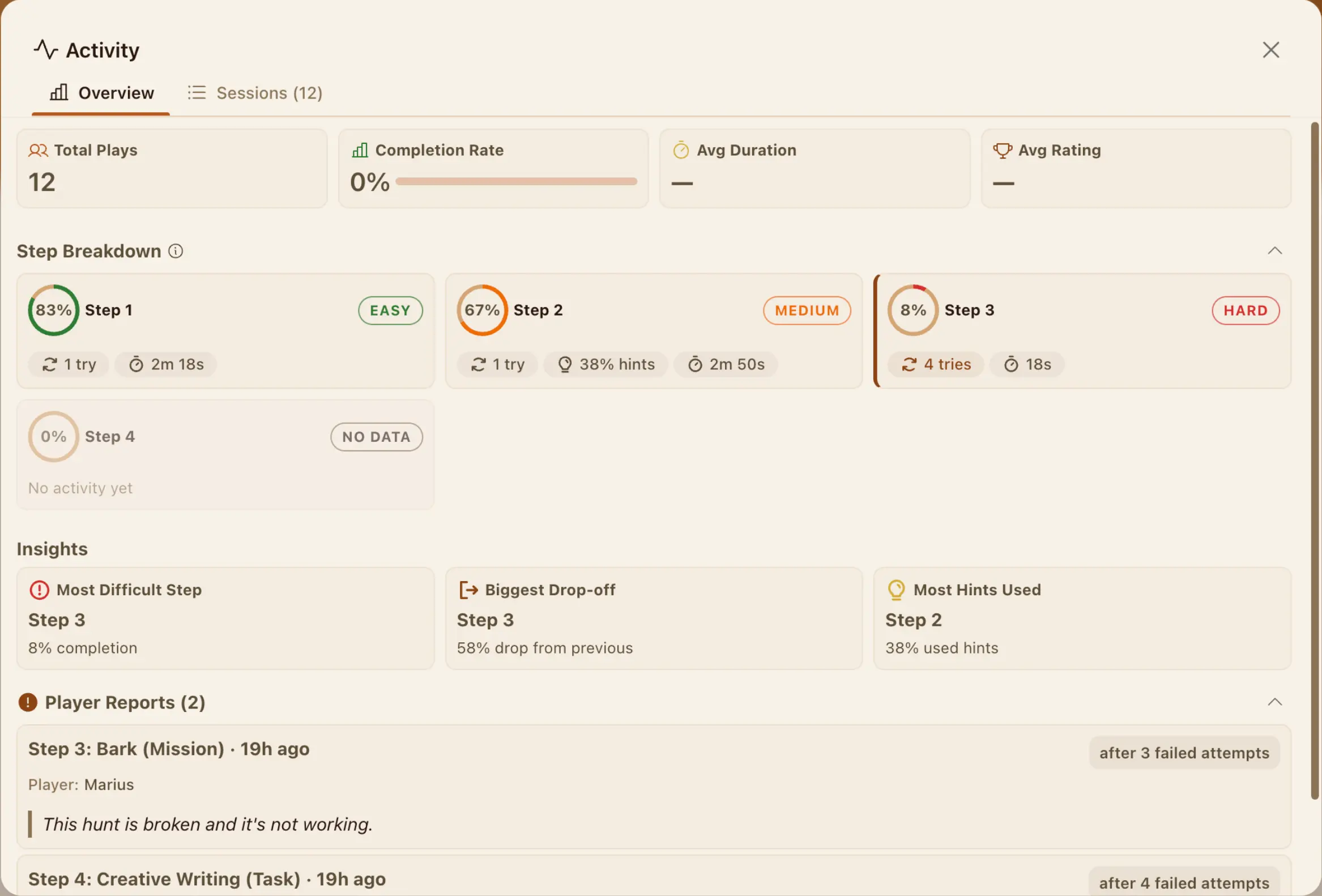
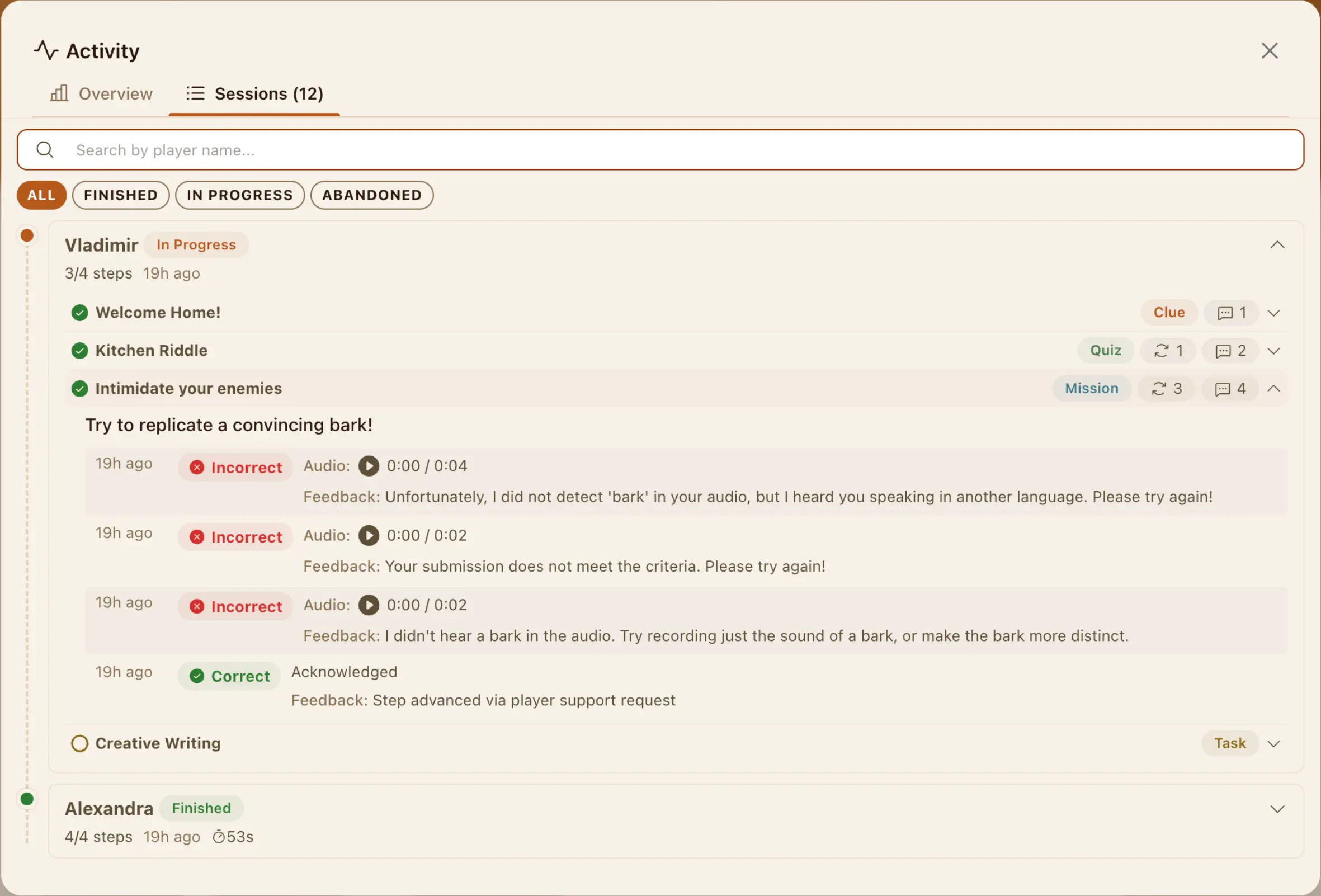
Builder Preview
The Builder embeds the Explorer in an iframe with a typed messaging layer. Same PlayerExporter as production. Preview matches exactly what real explorers see.
Hunt Sharing
Three permission levels (Owner, Admin, View) enforced in server-side middleware. The Builder adapts UI per role, but access control never relies on the client.
Form Auto-Save
Before sending an instruction to the AI, the Builder saves the current form state. The model always edits the latest data, not whatever was last persisted. After the edit completes, the form resets to the returned hunt while preserving the creator's step selection.
Prompt Trimming
The system prompt includes four fields per step: ID, type, title, mission type. Full data is one read call away if the model needs it. The model gets enough context to decide what to change without processing 50 fields per step on every request.
Compass Design System
@hunthub/compass wraps MUI's createTheme with shared tokens, typography scales, and responsive mixins. One import gives any app the full design system.
Media Processing
Images are compressed client-side before upload. Audio is captured at low bitrate through MediaRecorder. Only compressed files reach S3.
Reflections
The Hunt/HuntVersion separation was the strongest architectural decision. Optimistic locking on release, version-locked play sessions, and instant rollback all fall out naturally from the pointer model. It handles concurrent edge cases without pessimistic locks.
The step storage model is where the tradeoff didn't pay off. Steps as separate documents made publishing straightforward (clone the documents), but every read requires a secondary query. Embedding steps within HuntVersion would make the common read path a single document fetch. The publish operation gets more complex, but reads happen far more often than publishes.
The PlayerExporter boundary was worth every extra line of code. It turns a behavioral contract ("don't send answers to explorers") into a structural one that the type system enforces. Every new sensitive field on Step requires an explicit decision about whether StepPF carries it.
The iframe SDK is the riskiest integration boundary. Builder and Explorer deploy independently. A breaking change in the postMessage protocol would silently break preview with no compile-time warning. This needs contract tests between the two apps.
Links
- HedgeHunt, live product
- GitHub, private repo (available on request)